Project Overview
EDA and model building to classify the three species of flowers in the Iris flower dataset using Support Vector Machines.
In this project, we will be using the famous Iris flower dataset. We will be using a Support Vector Machine to classify data as one of three species of Iris. To optimize our model we will use GridSearch to experiment with our parameters qnd hopefully be able to improve our models accuracy.
Lastly, we will use pickle to save our model so that it can be deployed at a later stage as a stand-alone web application or as part of another application.
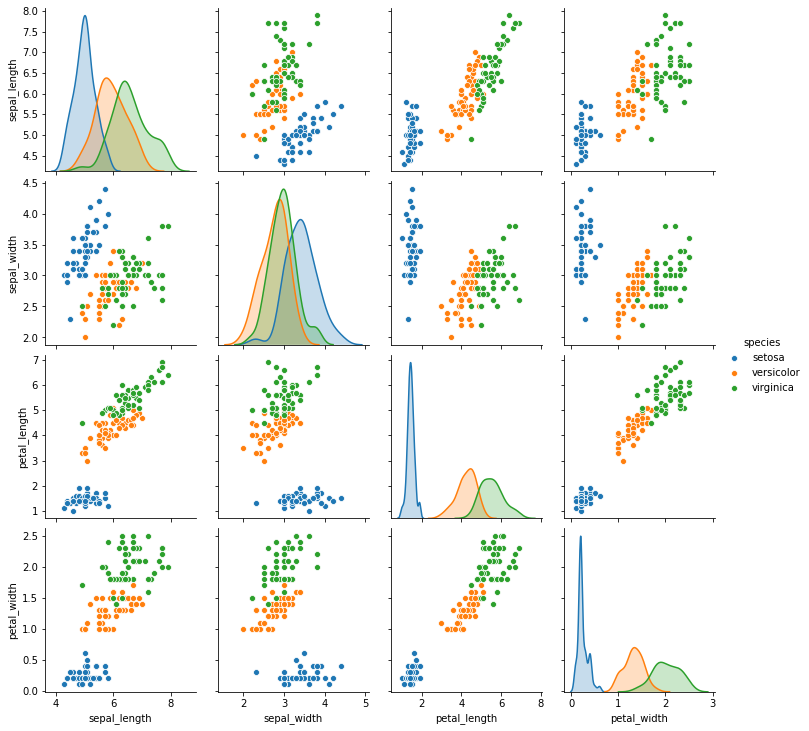 Pairplot of all numerical columns used to train our model
We look at variables such as sepal length, sepal width, petal length and petal width and how they correlate to each other. We then move onto explore these relations slightly more in depth.
Pairplot of all numerical columns used to train our model
We look at variables such as sepal length, sepal width, petal length and petal width and how they correlate to each other. We then move onto explore these relations slightly more in depth.
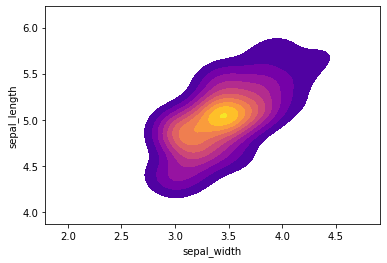 KDE plot of sepal length to sepal width of the species Setosa
In addition to this, we look at how these variables differ as per the species of flower (target variable). This helps us understand how each individual variable is influenced by the species of the flower.
Lastly, we train a base model of the SVM classifier following which we use a Grid Search cross validation to find more appropriate values for our parameters. We then train a model with these parameters and evaluate the model once again.
Head on over to the link below to check out the entire python notebook which contains a more in-depth exploration of the data along with various other visualizations.
KDE plot of sepal length to sepal width of the species Setosa
In addition to this, we look at how these variables differ as per the species of flower (target variable). This helps us understand how each individual variable is influenced by the species of the flower.
Lastly, we train a base model of the SVM classifier following which we use a Grid Search cross validation to find more appropriate values for our parameters. We then train a model with these parameters and evaluate the model once again.
Head on over to the link below to check out the entire python notebook which contains a more in-depth exploration of the data along with various other visualizations.