Project Overview
Our goal with this project is to compare the performance of different tree-based models on our LendingClub data in order to try and predict the probability of loan repayment.
For this project we will be exploring publicly available data from LendingClub.com. Lending Club connects people who need money (borrowers) with people who have money (investors).
As an investor, you would want to invest in people who showed a profile of having a high probability of paying you back. We will try to create a model that will help predict this so as to prevent the defaulting of loan payments. Our primary objective, however, is to understand how various tree-based models works on our data and how well they perform with respect to each other.
Our dataset has already been cleared of all null values and so we can overlook this step during our data preprocessing.
We begin by exploring our data with the help of a few visualizations. This helps us understand how different input features correlate to our target variable.
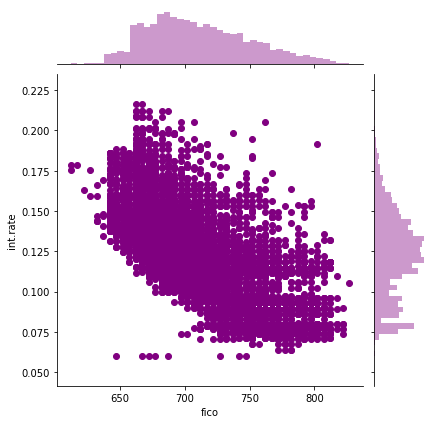 Correlation between FICO score and interest rate
We also look at visualizations such as the one below to understand how features such as credit policy influence customers FICO scores.
Correlation between FICO score and interest rate
We also look at visualizations such as the one below to understand how features such as credit policy influence customers FICO scores.
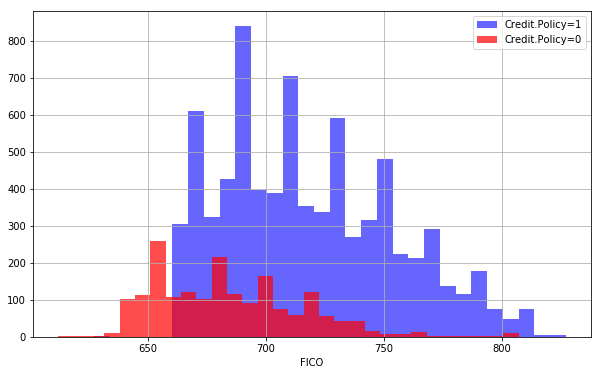 FICO score with respect to credit policy
We initially try out a very simple decision tree model to see how well it performs on our data. We then move on to Random Forest and Gradient Boosting models and use Randomized Cross Validation and Grid Search CV to check if we can optimize our models. Lastly, we evaluate each of these models to see which has performed the best on our dataset.
Head over to the link below to check out the entire python notebook which contains a more in-depth exploration of the data along with the steps involved in training our model and evaluating its performance.
FICO score with respect to credit policy
We initially try out a very simple decision tree model to see how well it performs on our data. We then move on to Random Forest and Gradient Boosting models and use Randomized Cross Validation and Grid Search CV to check if we can optimize our models. Lastly, we evaluate each of these models to see which has performed the best on our dataset.
Head over to the link below to check out the entire python notebook which contains a more in-depth exploration of the data along with the steps involved in training our model and evaluating its performance.