Project Overview
This project contains a brief analysis of the anonymized dataset using some basic statistical tools and charts. The primary objective is to use the K Nearest Neighbors algorithm to correctly classify our data.
It looks into how features are correlated with each other. We then standardize our features in order to be able to feed the data into our KNN algorithm.
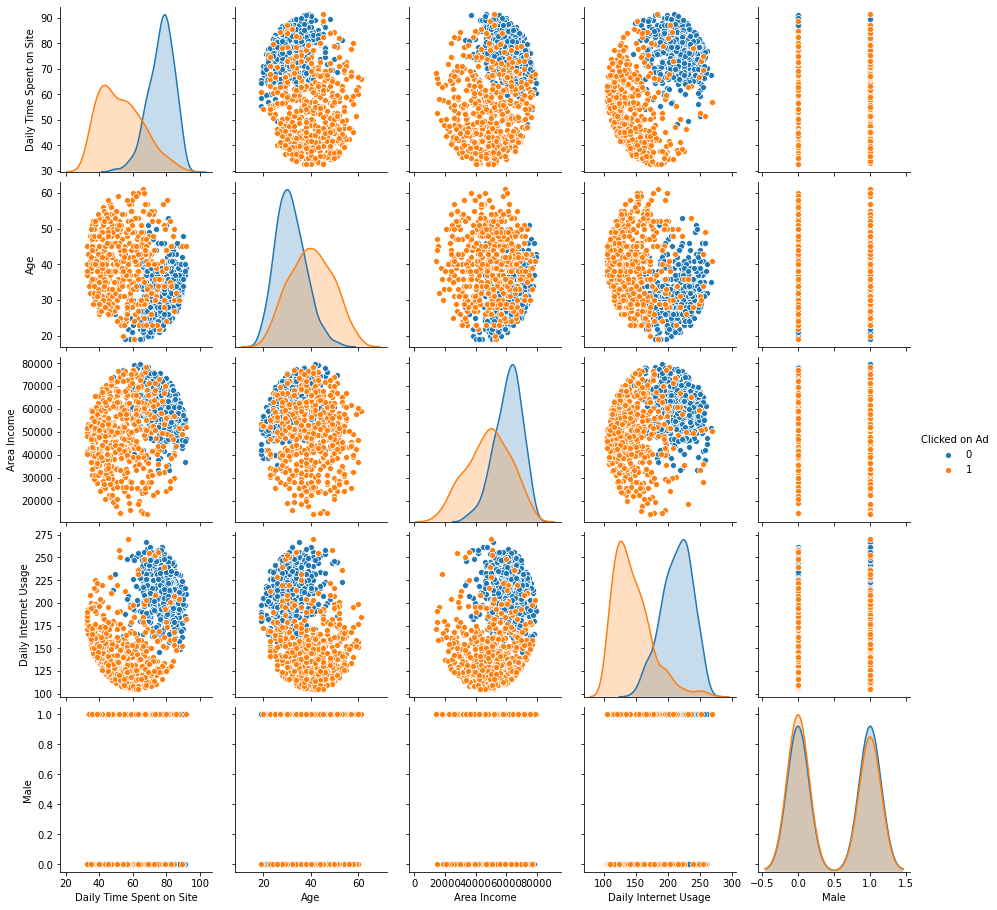 Correlation between features of our dataset with target variable as hue
We use the elbow method to estimate a good value for k and then train our model with this new k value.
Lastly, we look at certain metrics and visualization in order to evaluate the model and see how well it is able to predict whether the user has clicked on the ad or not.
Correlation between features of our dataset with target variable as hue
We use the elbow method to estimate a good value for k and then train our model with this new k value.
Lastly, we look at certain metrics and visualization in order to evaluate the model and see how well it is able to predict whether the user has clicked on the ad or not.
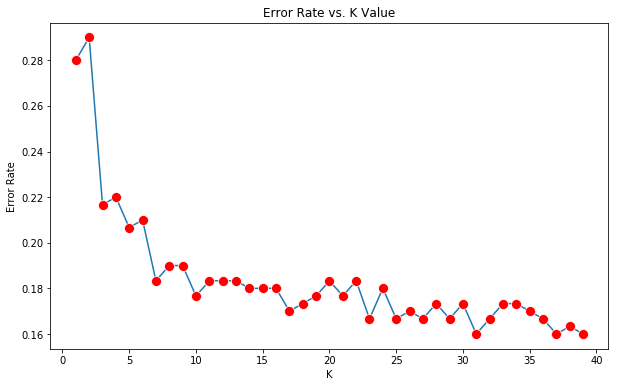 Elbow method to plot k values with error rate
Using scikitlearn and the KNN model, we then predict on our test data to classify our data into one of the classes in our target variable. We then evaluate this newly trained model.
Head over to the link below to check out the entire python notebook which contains a more in-depth exploration of the data along with the steps involved in training the scaling the features, using the elbow method to select a value for k and lastly evaluating our models.
Elbow method to plot k values with error rate
Using scikitlearn and the KNN model, we then predict on our test data to classify our data into one of the classes in our target variable. We then evaluate this newly trained model.
Head over to the link below to check out the entire python notebook which contains a more in-depth exploration of the data along with the steps involved in training the scaling the features, using the elbow method to select a value for k and lastly evaluating our models.